

The Dawn of Self-Evolving AI: How Agents Are Learning to Improve Themselves



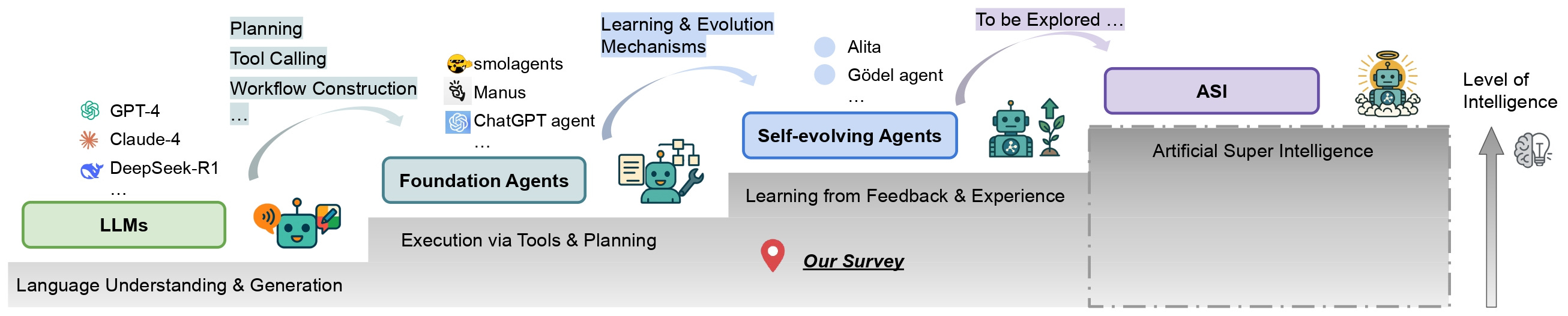
In a trailblazing shift that could reshape artificial intelligence as we know it, researchers are developing AI systems that can autonomously improve themselves through experience—potentially paving the way toward artificial super intelligence. A comprehensive new survey from an international team of researchers maps out this emerging field of "self-evolving agents," highlighting how these systems could transform everything from software development to healthcare.
The Next Frontier in AI: Systems That Improve Themselves
The latest generation of large language models (LLMs) like GPT-4 and Claude have demonstrated remarkable capabilities across diverse tasks. Yet these systems remain fundamentally static—once deployed, they cannot adapt their internal parameters when facing new tasks or evolving knowledge domains.
This limitation becomes particularly problematic in open-ended, interactive environments where conventional knowledge retrieval mechanisms prove inadequate. The solution? Self-evolving agents—AI systems designed to continuously learn from data, interactions, and experiences in real-time.
"We're witnessing a conceptual shift in artificial intelligence," explains the research team in their survey. "Instead of simply scaling up static models, we're developing systems that can dynamically adapt their perception, reasoning, and actions based on real-world feedback."
This shift is driving AI development toward what some researchers consider a promising path to Artificial Super Intelligence (ASI)—systems that not only learn and evolve from experience at unprecedented rates but also perform at or above human-level intelligence across a wide array of tasks.
What Makes an Agent "Self-Evolving"?
Unlike static LLMs, self-evolving agents are designed to overcome limitations by continuously learning from real-world feedback. The survey organizes these systems around three fundamental questions:
What aspects of an agent should evolve? This includes the model itself, the context (memory and prompts), tools, and the overall architecture.
When should adaptation occur? Evolution can happen during task execution (intra-test-time) or between tasks (inter-test-time).
How should that evolution be implemented? Methods include reward-based learning, imitation learning, and population-based evolutionary approaches.
The researchers define a self-evolving agent as a system that can transform itself based on its experiences. This transformation might involve updating its underlying model, refining its memory or instructions, creating new tools, or modifying its overall architecture.
Components That Can Evolve
The Model: Learning from Self-Generated Data
At the core of self-evolving agents is their ability to refine their parameters through experience. Unlike traditional methods that rely on human-annotated datasets, these agents can generate their own training data.
For example, the Self-Challenging Agent (SCA) alternates between generating coding problems and solving them, then fine-tunes itself using successful solutions. Other approaches like SELF, SCoRe, and PAG interpret execution traces or natural-language critiques as reward signals, enabling continuous policy improvement.
"These advancements chart a clear trajectory—from agents autonomously crafting their training tasks to directly refining their parameters based on execution feedback," the researchers note.
Context: Evolving Memory and Instructions
Another critical component is the agent's context—the information it uses to make decisions. This includes both memory (what the agent remembers from past interactions) and prompts (how instructions are phrased).
Memory evolution focuses on what knowledge an agent retains and how it organizes that information. Systems like Mem0 implement a two-phase pipeline where the agent first extracts important facts from recent dialogue and then decides how to update its long-term memory—adding new facts, merging redundant ones, or deleting contradictions.
Prompt optimization, meanwhile, enables agents to refine the instructions they follow. Methods like APE generate candidate prompts, score them on validation examples, and select the best. More advanced approaches like SPO create a fully self-contained loop where the model generates its training data and uses pairwise preference comparison to refine prompts without external labeled data.
Tools: From Users to Makers
Perhaps most fascinating is the evolution of tools—the capabilities an agent can use to interact with its environment. The survey highlights a crucial transition: from agents being mere tool users to becoming autonomous tool makers.
"This transition from relying on predefined, static toolsets to enabling agents to autonomously expand and refine their own skills is a critical leap towards cognitive self-sufficiency," the researchers explain.
This evolution happens across three fronts:
Tool Discovery and Creation: Systems like Voyager build an expanding library of skills through trial-and-error in complex environments like Minecraft. Others like Alita search open-source code repositories or write new functions when they identify a capability gap.
Mastery Through Refinement: Frameworks like LearnAct establish a self-correction loop where agents learn from their own experiences, analyzing feedback signals to debug and improve their tools.
Management and Selection: As an agent's skill library grows, the challenge shifts to efficiently managing and selecting from potentially thousands of tools. ToolGen addresses this by encoding tools as unique tokens within the language model's vocabulary, reframing tool retrieval as a generation problem.
Architecture: Optimizing the System Itself
The most advanced self-evolving agents can modify their own internal architecture—treating their fundamental structure and logic as learnable components.
At the single-agent level, systems like AgentSquare define a modular design space of components (planners, memory modules, etc.) and use evolutionary algorithms to find the most effective combination. More radical approaches like the Darwin Gödel Machine recursively modify their own Python codebase.
For multi-agent systems, frameworks like ADAS and AFlow treat system design as a search problem, using techniques like Monte Carlo Tree Search to efficiently navigate the enormous design space of possible configurations.
When Evolution Happens
Self-evolution can occur at different times in an agent's lifecycle:
During Task Execution (Intra-test-time)
Some agents adapt while solving problems. For example, Reflexion analyzes its own performance, generates verbal critiques, and maintains these reflections in memory to guide subsequent decisions. AdaPlanner goes further by dynamically revising its entire approach based on environmental feedback, switching between action execution and plan modification as needed.
"These methods demonstrate how test-time adaptation can achieve sophisticated behavioral modification without permanent model changes," the survey notes.
Between Tasks (Inter-test-time)
Most self-evolution happens after task completion. SELF generates responses to unlabeled instructions and enhances them through self-critique. STaR focuses on reasoning improvement—models attempt problems, then generate explanations for correct answers they initially failed to solve, creating augmented training data.
This retrospective learning process allows agents to consolidate experiences, identify patterns of success and failure, and systematically refine their behavioral policies without the computational constraints of real-time task demands.
How Agents Evolve
The survey identifies three main approaches to implementing self-evolution:
Reward-based Evolution
This approach centers on designing reward signals to guide iterative self-improvement. These signals can take various forms:
Textual Feedback: Natural language critiques and suggestions, as used in frameworks like Reflexion and AdaPlanner.
Internal Confidence: Metrics derived from the model's probability estimates or certainty, as in Self-Rewarding Language Models.
External Rewards: Signals from the environment, majority voting, or explicit rules.
Implicit Rewards: The "Reward Is Enough" framework demonstrates that LLMs can learn from simple scalar signals embedded in the context window without explicit reinforcement learning.
Imitation and Demonstration Learning
This paradigm focuses on learning from high-quality examples:
Self-Generated Demonstrations: STaR enables language models to bootstrap their reasoning capabilities by generating reasoning chains for problems, fine-tuning on correct solutions, and repeating this cycle.
Cross-Agent Demonstrations: SiriuS maintains an experience library containing successful interaction trajectories generated by different agents, facilitating knowledge sharing.
Hybrid Approaches: RISE enables agents to introspect on their reasoning processes, identify areas for improvement, and generate corrective demonstrations.
Population-based and Evolutionary Methods
Drawing inspiration from biological evolution, these approaches maintain multiple agent variants simultaneously:
Single-Agent Evolution: The Darwin Gödel Machine maintains an archive of all historical versions, enabling branching from any past "species" rather than linear optimization.
Multi-Agent Evolution: EvoMAC implements "textual backpropagation" where compilation errors and test failures serve as loss signals to drive iterative modifications of agent team composition.
Real-World Applications
Self-evolving agents are already showing promise across various domains:
Coding and Software Development
SICA demonstrates that a self-improving coding agent can autonomously edit its own codebase and improve performance on benchmark tasks. EvoMAC automatically optimizes individual agent prompts and multi-agent workflows, significantly improving code generation performance.
The Dawn of Embodied AI: How Intelligent Agents Are Learning to Model Our World

In a significant leap forward for artificial intelligence, researchers at Meta AI have unveiled a comprehensive framework for developing AI agents that can perceive, understand, and interact with the physical world. Their groundbreaking research, detailed in a recent paper, outlines how embodied AI agents—ranging from virtual avatars to wearable devices…
AgentCoder uses a multi-agent framework where a programmer agent continuously improves code based on feedback from a test executor agent, validated against independent test cases from a test designer.
Graphical User Interfaces (GUI)
Self-evolving GUI agents extend LLM capabilities to direct manipulation of desktop, web, and mobile interfaces. The Navi agent replays and critiques its own failure trajectories, doubling its task-completion rate across 150 Windows challenges. WebVoyager fuses screenshot features with chain-of-thought reflection, raising its end-to-end success on unseen sites from 30% to 59%.
Financial Applications
QuantAgent uses a two-layer framework that iteratively refines responses and automatically enhances its domain-specific knowledge base using feedback from simulated and real-world environments. This reduces reliance on costly human-curated datasets and improves predictive accuracy in trading tasks.
TradingAgents incorporates dynamic processes like reflection, reinforcement learning, and feedback from real-world trading results to continuously refine strategies and enhance trading performance.
Healthcare
Agent Hospital creates closed environments with LLM-driven doctors, patients, and nurses, allowing the doctor agent to treat thousands of virtual cases. This helps agents autonomously refine diagnostic strategies without manual labeling.
MedAgentSim records successful consultations as reusable trajectories and employs chain-of-thought reflection to drive self-evolution, improving success rates over successive interactions.
Education
PACE adjusts its prompts based on detailed student profiles and continually refines its questioning during conversations. An LLM-to-LLM self-play framework generates diverse tutor-student dialogues that further fine-tune the agent.
EduPlanner frames lesson-plan creation as an adversarial loop where a planner's draft is repeatedly reviewed and refined by evaluator and optimizer agents until it meets diverse educational goals.
Challenges and Future Directions
Despite promising advances, several challenges remain:
Personalization
Enabling AI agents to accurately capture and adapt to users' unique behavioral patterns remains difficult. The cold-start problem persists: agents need to progressively refine their understanding with limited initial data. Challenges in personalized planning and execution include effective long-term memory management and ensuring outputs consistently align with individual user preferences.
Generalization
Self-evolving agents face a fundamental tension between specialization and broad adaptability. Designing scalable architectures that maintain performance as complexity increases remains challenging. Cross-domain adaptation is another frontier—current methods often rely on domain-specific fine-tuning, restricting adaptability to new environments.
Safety and Control
As agents become more capable of learning and evolving independently, safety concerns grow. These include user-related risks (vague instructions leading to harmful actions) and environmental risks (exposure to malicious content). Current agents still struggle to accurately differentiate between necessary and irrelevant information.
Multi-Agent Ecosystems
Balancing independent reasoning with effective group decision-making in multi-agent environments presents unique challenges. Agents often risk becoming overly reliant on group consensus, diminishing their independent reasoning capabilities. Developing efficient frameworks that allow agents to collaborate while preserving their individual strengths remains an open problem.
Evaluation: Measuring Progress
Evaluating self-evolving agents requires going beyond traditional metrics to capture their dynamic, adaptive capabilities. The survey proposes five core dimensions:
Adaptivity: How well an agent improves performance through experience, measured by success rate over iterations.
Retention: The agent's ability to retain previously learned knowledge, quantified by metrics like Forgetting (FGT) and Backward Transfer (BWT).
Generalization: How well an agent applies accumulated knowledge to new, unseen domains.
Efficiency: The resourcefulness of an agent, measured by token consumption, time expenditure, and number of steps required.
Safety: Whether agents develop unsafe behavioral patterns during evolution, assessed through safety scores and harm metrics.
The researchers also distinguish between three evaluation paradigms: static assessment (evaluating performance at a specific point), short-horizon adaptive assessment (measuring improvement over limited interactions), and long-horizon lifelong learning assessment (tracking continuous learning across diverse tasks over extended periods).
The Road to Artificial Super Intelligence
The survey positions self-evolving agents as precursors to Artificial Super Intelligence—systems that can learn and evolve from experience at unprecedented rates while performing at or above human-level intelligence across diverse tasks.
"By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive, robust, and versatile agentic systems in both research and real-world deployments," the researchers conclude.
As these systems continue to develop, they could transform how we interact with AI—shifting from static tools to dynamic partners that grow and adapt alongside us, continuously improving their capabilities based on our needs and feedback.
I found the newsletter truly compelling, highlighting how “self‑evolving agents” are shifting AI from static tools into systems that continuously refine themselves based on real-world experience. The mapped survey offers a very structured understanding of what develops, when, and how. What concerns me most is how oversight and safety protocols will keep pace.