

AI Agents Can Complete Tasks Without Understanding Their World, Study Reveals


Scientists at Fudan University have uncovered a troubling gap in how artificial intelligence agents navigate virtual environments: Large Language Models can successfully complete assigned tasks while barely understanding the world around them. The research team tested 30 different environments and discovered that task completion rates plummeted from 100% to 43% as difficulty increased, yet the agents’ actual understanding of their surroundings remained oddly stable at around 50%. This disconnect challenges fundamental assumptions about how we measure AI capabilities.
The finding matters because AI agents are increasingly deployed in real-world scenarios. From web navigation assistants to software engineering tools, these systems make decisions that affect everyday users. If an agent can successfully book your flight but doesn’t actually comprehend airport layouts or connection logistics, what happens when something goes wrong?
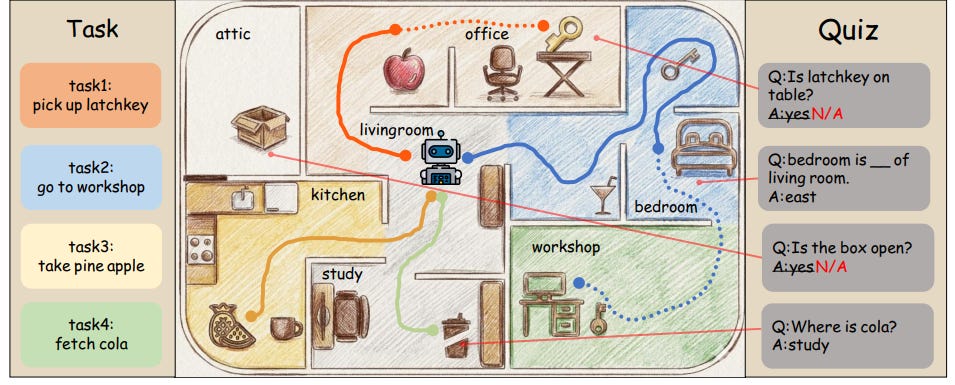
The research introduces a new evaluation framework called Task2Quiz, which separates “doing” from “knowing” by testing whether agents truly grasp the environments they operate within.
Current evaluation methods focus almost exclusively on whether AI agents reach their goals. Did the agent find the apple? Did it navigate to the correct room? These trajectory-based metrics measure success without examining comprehension. The Fudan research team, led by Siyuan Liu and colleagues, argues this approach creates a dangerous illusion of competence. An agent might stumble through a task using narrow heuristics while possessing zero transferable knowledge about the underlying world structure.
The implications extend beyond academic curiosity. As organizations integrate AI agents into critical workflows, understanding the difference between task completion and genuine environmental understanding becomes essential for safety and reliability. The research team created T2QBench, a comprehensive benchmark comprising 1,967 carefully designed questions across five categories: location, connectivity, direction, key-lock matching, and object properties. Their findings suggest we’ve been measuring the wrong things all along.
The Task2Quiz Framework Exposes Knowledge Gaps
The researchers designed a two-stage evaluation system that reveals what AI agents actually know about their operational environments. Stage one presents agents with coverage-oriented tasks designed to maximize exploration rather than optimize for single goals. Unlike traditional benchmarks that might ask an agent to simply “fetch the apple,” these tasks force interaction with diverse rooms, objects, and constraints. The system generates task sets using a weighted set cover algorithm that ensures comprehensive environmental exposure
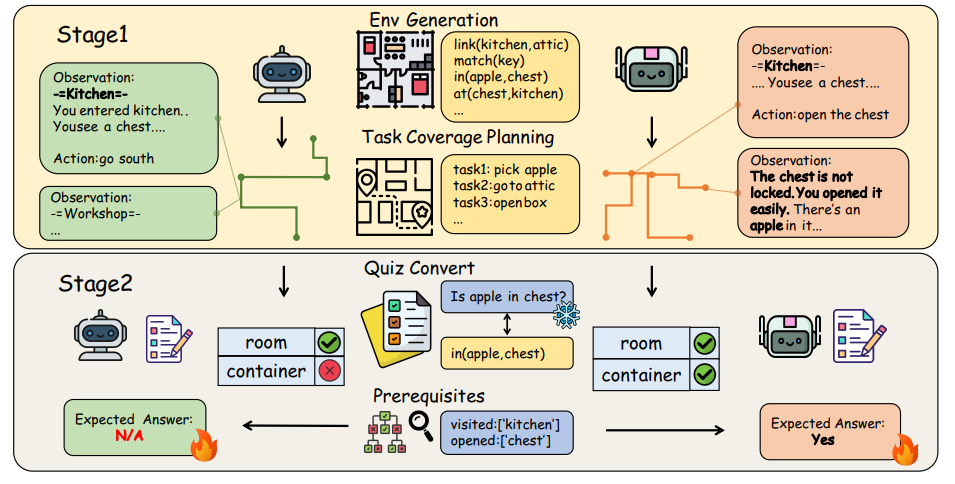
Stage two administers quizzes based on what agents encountered during exploration. Here’s where things get interesting. The quiz questions aren’t generic—they’re dynamically generated based on each agent’s specific interaction history and the known environment metadata. If an agent never visited the kitchen, questions about kitchen contents are marked “non-answerable” to avoid unfair penalties. This prerequisite checkpoint system creates trajectory-conditioned evaluation that separates failures of exploration from failures of comprehension.
The quiz taxonomy probes five distinct knowledge dimensions. Location questions test whether agents know where objects reside. Connectivity questions examine understanding of traversable links between rooms. Direction questions assess spatial orientation requiring cross-turn reasoning. Match questions verify whether agents grasp which keys unlock which doors. Property questions probe latent object states like locked versus unlocked or open versus closed.
Testing occurred across three difficulty levels spanning 30 total environments. Easy environments contained 3-5 rooms with 6-10 objects. Medium environments expanded to 6-10 rooms with 14-18 objects. Hard environments reached 16-20 rooms with 28-32 objects. The team evaluated prominent models including GPT-4, DeepSeek-V3, ChatGLM-4, and Qwen3-32B across multiple memory configurations.
Results painted a stark picture. GPT-4 achieved 68.75% task success but only 50.23% environment understanding. DeepSeek-V3 with in-context memory reached 63.84% task completion yet managed just 54.25% on comprehension quizzes. Even more concerning, memory-augmented systems frequently underperformed simple in-context baselines. The sophisticated memory mechanisms designed to help agents retain environmental knowledge often discarded critical fine-grained details during abstraction.
Memory Systems Fail to Capture Environmental Understanding
The research team compared naive in-context approaches against three memory-augmented systems: Mem0, LangMem, and A-MEM. These systems implement different strategies for organizing and retrieving interaction history. Conventional wisdom suggests explicit memory mechanisms should outperform simple context retention, especially as environments grow complex. The data revealed otherwise.
ChatGLM-4 with basic in-context memory achieved 61.16% task success and 52.41% environment understanding. When equipped with Mem0 memory augmentation, task performance collapsed to 39.29% while understanding dropped to 46.21%. LangMem recovered some ground with 51.34% task completion and 51.65% understanding. A-MEM managed 42.86% and 48.30% respectively. The pattern held across models—memory systems helped organization less than they hurt fidelity.
Why do sophisticated memory mechanisms underperform? The researchers identified a critical flaw: current systems optimize for event-centric summaries rather than spatial-structural representations. When an agent explores a room, interacts with objects, and discovers relationships, memory systems attempt to compress these experiences into high-level abstractions. The compression discards precisely the environmental details needed for genuine understanding.
Consider how humans build mental maps. We don’t just remember that we accomplished task X in location Y. We construct spatial models with directions, distances, object placements, and relationship networks. Current AI memory systems lack mechanisms for this kind of grounded world-state representation. They remember actions and outcomes without encoding the persistent environmental structure that makes knowledge transferable.
DeepSeek-V3 demonstrated this pattern clearly. The in-context baseline achieved 68.41% accuracy on location questions and 59.48% on connectivity questions. With Mem0 augmentation, location accuracy dropped to 61.87% while connectivity remained at 60.66%. LangMem improved location understanding to 66.94% but connectivity fell to 57.35%. No memory system exceeded the simple baseline’s overall performance.
The team analyzed answer patterns across question types to understand what agents actually learned. Models performed best on location questions, averaging above 60% accuracy. These questions often require only single-turn retrieval from recent observations. Performance degraded for connectivity and direction questions demanding multi-turn reasoning. The steepest drop occurred on property questions, where agents averaged below 35% accuracy across all configurations.
Exploration Emerges as the Dominant Bottleneck
Property questions expose a fundamental limitation in current agent architectures. To answer whether a box is locked, an agent must actually attempt opening it. To determine if a door leads north or south, the agent must traverse it and observe directional changes. These questions demand proactive interaction beyond minimal task completion.
Agents optimize for efficiency rather than exploration. Given a task to “fetch the apple from the kitchen,” an optimal agent follows the shortest path, grabs the apple, and returns. It never investigates the locked chest in the corner. It doesn’t test whether the mysterious key matches any doors. It ignores most environmental elements irrelevant to immediate goals.
The research quantified this exploration deficit through prerequisite checkpoints. Many quiz questions became non-answerable because agents never visited required locations or performed necessary interactions. When the team analyzed which questions agents could theoretically answer based on their trajectories, they found that insufficient exploration explained more failures than poor memory or reasoning.
Qwen3-32B with in-context memory demonstrated this pattern. Despite achieving only 34.38% task success, it managed 58.55% environment understanding—the highest among tested configurations. This counterintuitive result suggests that failed task attempts sometimes produce more exploratory behavior than successful streamlined solutions. Agents that struggle and backtrack inadvertently gather broader environmental knowledge.
The direction question performance particularly illuminated the exploration bottleneck. All models scored below 60% on directional queries despite these being answerable through simple observation. The issue wasn’t reasoning complexity—agents simply never traversed enough paths to build coherent spatial models. They completed tasks without mapping the world.
Match questions presented another challenge. Key-lock matching requires trying different keys on different locks, an interaction agents avoid unless specifically required by task constraints. Average accuracy hovered around 40% across models, far below the performance on simpler location questions. Agents pursued efficiency over environmental discovery.
The Illusion of Competence in Current Benchmarks
Traditional agent benchmarks create measurement theater. They report impressive success rates on task completion while remaining silent about underlying comprehension. An agent scoring 85% on web navigation tasks might understand nothing about webpage structure, browser state, or navigation principles. It simply learned heuristics mapping specific observations to specific actions.
The Task2Quiz framework revealed this illusion across difficulty levels. On easy environments, ChatGLM-4 achieved perfect 100% task success. The Environment Understanding Score for the same configuration? Just 58%. As difficulty increased to medium levels, task success dropped to 85% while understanding remained flat at 50%. Hard environments saw task completion collapse to 43%, yet understanding held steady at 51%.
This divergence demolishes the assumption that task metrics proxy for knowledge. Success rates track trajectory difficulty—longer solutions, tighter constraints, more complex planning. Understanding scores measure something fundamentally different: whether agents construct grounded, transferable models of their operational environments. The two dimensions move independently.
Consider the implications for real-world deployment. Web navigation agents might successfully complete booking workflows while completely misunderstanding website structure. If the interface changes slightly or an unexpected error appears, these agents lack the environmental model needed to adapt. They’ve optimized for specific paths through specific scenarios without building robust world knowledge.
The research team tested this hypothesis by varying environment layouts while keeping task structures similar. Agents that succeeded on environment A frequently failed on environment B despite identical task objectives. The failures occurred not from planning errors but from inability to transfer spatial understanding across similar but distinct topologies. They never built portable environmental models.
GPT-4’s performance illustrated the pattern. Across all difficulty levels, it maintained around 50% environment understanding despite widely varying task success rates. The model learned to navigate specific instances without acquiring generalizable knowledge about room connectivity, object placement, or spatial relationships. Each environment remained a fresh puzzle rather than an instance of familiar patterns.
Implications for AI Agent Development
These findings challenge core assumptions in agent architecture design. Current systems combine large language models with planning algorithms, memory systems, and tool-use frameworks. The implicit assumption: agents that complete tasks successfully must be learning useful environmental representations. The data suggests otherwise.
Developers optimizing for task completion metrics inadvertently select against environmental understanding. Efficiency pressures reward agents that find shortest paths and minimal interaction sequences. Exploration behaviors that would build comprehensive world models get penalized as wasteful. The resulting agents excel at narrow optimization while remaining fundamentally brittle.
The research points toward three critical development priorities. First, agent architectures need explicit mechanisms for spatial-structural representation distinct from event-centric memory. Current systems compress interaction histories into summaries optimized for action selection. Environmental understanding requires different abstractions: maps, relationship graphs, property databases, and constraint networks.
Second, training and evaluation must incorporate exploration incentives beyond task completion. Agents need reward signals for discovering environmental features, mapping spatial relationships, and uncovering latent properties. Simply completing assigned tasks faster provides insufficient signal for building transferable world models. The coverage-oriented task generation in Task2Quiz offers one approach—synthetic objectives designed to maximize environmental exposure.
Third, evaluation frameworks must separate doing from knowing. Task success rates measure one dimension of capability. Environment understanding scores measure a complementary dimension essential for generalization. Comprehensive agent evaluation requires both metrics along with analysis of how they diverge across difficulty levels and environmental variations.
The research team identified proactive exploration as the dominant bottleneck. Memory systems and reasoning improvements matter, but they operate on top of environmental knowledge that must first be acquired. Agents that never attempt opening locked containers can’t learn about locking mechanisms. Agents that never traverse optional paths can’t discover spatial relationships.
This exploration deficit stems partly from language model training. Large language models learn from text documenting completed tasks and successful outcomes. The training data contains limited examples of exploratory behavior, failed attempts, or systematic environmental investigation. Models inherit this bias toward goal-directed efficiency over comprehensive understanding.
Future Directions for More Capable Agents
The Task2Quiz paradigm opens new research directions for improving agent capabilities. One promising avenue involves curriculum learning that gradually increases environmental complexity while maintaining exploration incentives. Agents might first master simple environments where thorough investigation remains tractable before progressing to larger, more complex scenarios.
Another direction explores hybrid architectures combining symbolic reasoning with neural learning. The TextWorld framework used in this research maintains explicit symbolic representations of environmental state. Future agents might leverage similar structured representations while using language models for flexible reasoning and action selection. This combination could preserve fine-grained environmental details lost in pure neural memory systems.
Multi-agent collaboration presents interesting possibilities. Individual agents with partial environmental knowledge might pool observations to construct more complete world models. Collaborative exploration strategies could systematically divide coverage responsibilities while sharing discoveries. The social learning demonstrated in human groups could inspire more effective AI exploration behaviors.
The researchers acknowledge limitations in their current approach. TextWorld environments remain relatively simple compared to commercial games or real-world scenarios. Extending the framework to more complex domains like Minecraft or robotic manipulation tasks would strengthen insights about environmental understanding across diverse settings. The computational costs of exhaustive state-space search for coverage task generation also limit scalability.
Nevertheless, the core insights appear robust. Across models, memory systems, and difficulty levels, the data consistently shows task success diverging from environmental understanding. Current agent architectures excel at optimizing specific trajectories while failing to build transferable world knowledge. This gap poses significant challenges for deploying AI agents in dynamic, evolving environments requiring adaptation and generalization.
The research provides a diagnostic foundation for developing more capable agents. By measuring both task completion and environmental understanding, researchers can identify which architectural components genuinely improve generalization versus simply optimizing narrow metrics. The prerequisite checkpoint system enables fair comparison across different exploration strategies by accounting for information accessibility.
Organizations deploying AI agents should consider these findings when evaluating system capabilities. High task success rates provide incomplete pictures of reliability and robustness. Agents lacking comprehensive environmental understanding may fail catastrophically when conditions shift or unexpected situations arise. Thorough evaluation across both dimensions offers better risk assessment for production deployments.
Understanding Versus Optimization in AI Systems
The distinction between doing and knowing extends beyond agent systems. Many AI applications demonstrate similar gaps between measured performance and genuine understanding. Computer vision models achieve high accuracy on benchmark datasets while remaining vulnerable to distribution shifts. Language models generate fluent text while exhibiting fundamental misconceptions about described scenarios.
This pattern suggests a deeper challenge in AI development: optimization pressure toward measurable metrics versus building robust, transferable knowledge. When evaluation focuses narrowly on task completion, systems learn to game those specific measures rather than acquire generalizable capabilities. The solution requires evaluation frameworks that probe multiple dimensions of competence.
The Task2Quiz approach offers a template applicable beyond text-based environments. Vision-language agents could face quizzes about spatial relationships, object properties, and scene structure after completing visual tasks. Robotic systems might answer questions about workspace layout, object affordances, and physical constraints following manipulation tasks. The core principle—separating successful behavior from environmental understanding—generalizes across domains.
Current benchmarks in web navigation, software engineering, and operating system interaction predominantly measure task completion. Extending these evaluations with environment-based quizzes could reveal whether agents truly understand webpage structure, code repositories, or file systems versus simply memorizing action sequences. The diagnostic insights would guide development toward more robust and generalizable systems.
The research demonstrates that sophisticated memory mechanisms don’t automatically improve environmental understanding. This finding challenges assumptions about agent architecture design. Simply adding memory systems or increasing model scale may not address fundamental limitations in how agents acquire and represent world knowledge. Purpose-built mechanisms for spatial reasoning, relationship mapping, and property tracking likely require explicit architectural support.
The exploration bottleneck identified in this research connects to broader questions about AI curiosity and intrinsic motivation. Human learners exhibit natural curiosity that drives exploration beyond immediate goals. Children investigate objects, test hypotheses, and build environmental models through playful interaction. Current AI agents lack comparable intrinsic motivation for environmental discovery, instead optimizing ruthlessly for assigned objectives.
Incorporating curiosity-driven exploration into agent architectures could address the bottleneck while improving environmental understanding. Agents rewarded for discovering novel environmental features, uncovering latent properties, or mapping unknown relationships might build more comprehensive world models. These models would support better generalization when facing new tasks or modified environments.
The implications extend to AI safety considerations. Agents that complete tasks without understanding their environments pose deployment risks. They may fail unpredictably when conditions change, pursue goals in unintended ways, or prove difficult to align with human intentions. Comprehensive environmental understanding provides grounding that makes agent behavior more interpretable and controllable.
Conclusion: Toward Truly Generalizable AI Agents
The Task2Quiz research reveals a fundamental gap between what AI agents do and what they know. High task success rates mask limited environmental understanding that undermines generalization. Current memory systems and evaluation paradigms fail to address this core limitation. Agents remain optimized for narrow efficiency rather than building transferable world models.
These findings arrive at a crucial moment for AI deployment. Organizations increasingly rely on agents for complex workflows spanning web navigation, software development, and system administration. Understanding the difference between task completion and genuine comprehension becomes essential for safe, reliable deployment. Agents lacking robust environmental understanding may succeed initially only to fail catastrophically when conditions shift.
The path forward requires architectural innovations supporting spatial-structural representation, evaluation frameworks measuring multiple competence dimensions, and training approaches incorporating exploration incentives. The deterministic, automated evaluation pipeline demonstrated in this research provides tools for measuring progress. As the field develops more capable agents, comprehensive assessment across both doing and knowing will separate genuine advances from narrow optimization.
Future AI systems must move beyond optimizing trajectories toward building grounded, transferable environmental models. The distinction between completing tasks and understanding worlds may determine whether agents achieve robust generalization or remain brittle specialists. This research provides both diagnostic tools and theoretical insights needed to develop the next generation of truly capable AI agents that can adapt, generalize, and operate reliably across diverse, dynamic environments.
Frequently Asked Questions
What is Task2Quiz and why does it matter?
Task2Quiz is a new evaluation framework that tests whether AI agents truly understand the environments they operate in, separate from just completing assigned tasks. It matters because current AI agents can successfully complete tasks while lacking the environmental knowledge needed to generalize or adapt when conditions change.
How does Task2Quiz differ from traditional AI benchmarks?
Traditional benchmarks measure task completion—whether agents reach goals. Task2Quiz separates “doing” from “knowing” by administering quizzes about environmental understanding after tasks are completed, revealing whether agents built transferable world models or just optimized specific trajectories.
What did researchers discover about AI memory systems?
Surprisingly, sophisticated memory-augmented systems often performed worse than simple in-context baselines. Current memory mechanisms compress interaction histories in ways that discard fine-grained environmental details essential for understanding, helping organization less than they hurt fidelity.
What is the main bottleneck preventing AI agents from understanding environments?
Insufficient exploration emerged as the dominant bottleneck. Agents optimize for efficient task completion using shortest paths and minimal interactions, never discovering environmental features irrelevant to immediate goals. They succeed at specific tasks without building comprehensive world models.
How big was the gap between task success and environmental understanding?
Dramatic. On easy environments, some agents achieved 100% task success with only 58% environmental understanding. As difficulty increased, task success dropped to 43% while understanding remained stable around 50%, showing these dimensions move independently.
What are the implications for real-world AI deployment?
Agents lacking environmental understanding may fail unpredictably when conditions change or unexpected situations arise. High task success rates can mask fragility, creating deployment risks in production systems handling web navigation, software engineering, or system administration.
How can AI development address these limitations?
Three priorities emerged: building explicit mechanisms for spatial-structural representation distinct from event memory, incorporating exploration incentives beyond task completion, and evaluating both doing and knowing dimensions to measure genuine capability rather than narrow optimization.